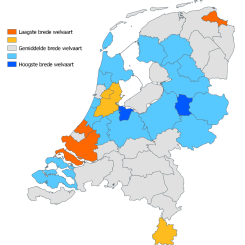
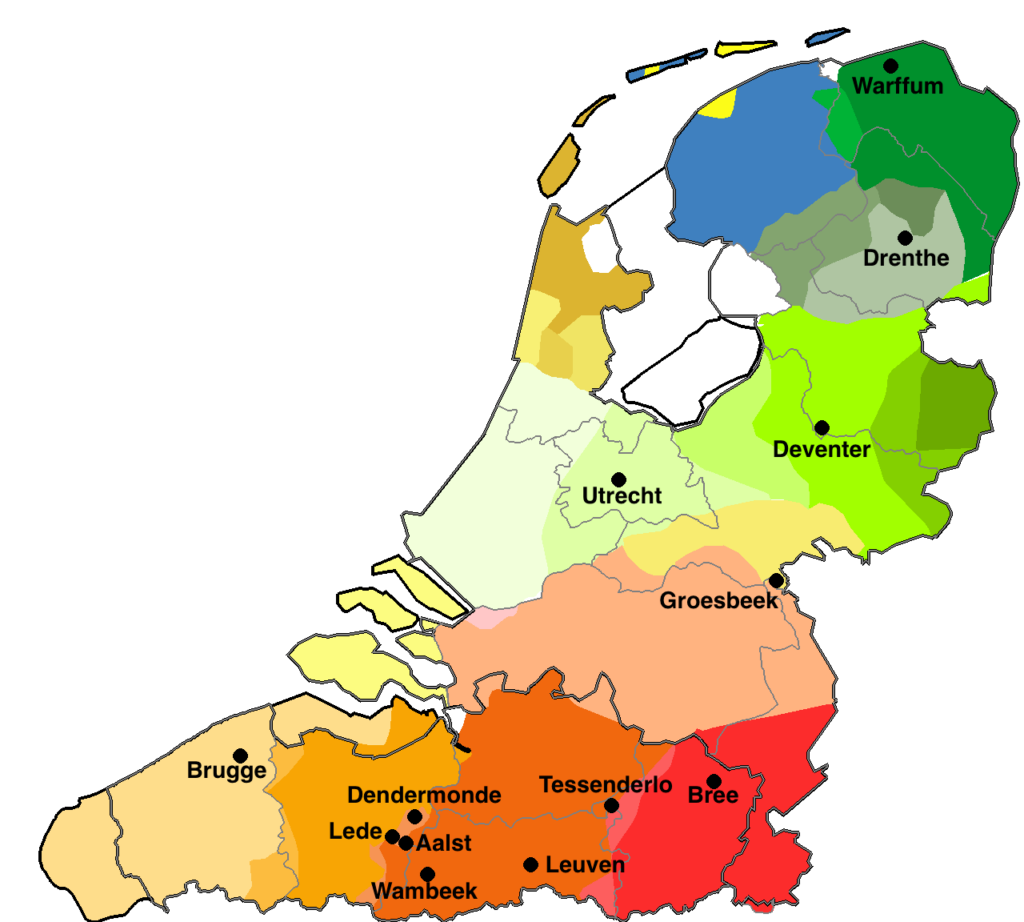
In our portfolio below, you can find a collection of projects by the different teams of the Centre for Digital Humanities. Use the filters to browse through the projects per team and per topic, and use the 'Current' button to see only projects that we are currently working on.